AI Cookbook Competition - Month Three
A little over two months ago I wrote about the first round of the AI cookbook competition. Since then there have been two further rounds and a considerable amount of further progress. For the latest round I was able to get the error score down to 10.867 using an additional image pre-processing step and then a variety of text clean-up improvements.
Image Pre-processing
Ian, who writes the AI Cookbook, had the theory that the curved text present at the top of many of the plaques in the test set were causing tesseract, our OCR software of choice, significant problems in transcribing the main text. If we could automatically recognise the curved text and block it out the transcription should be significantly improved. In the diagram below the text we want to be transcribed is in green and the text we don't want is in red.

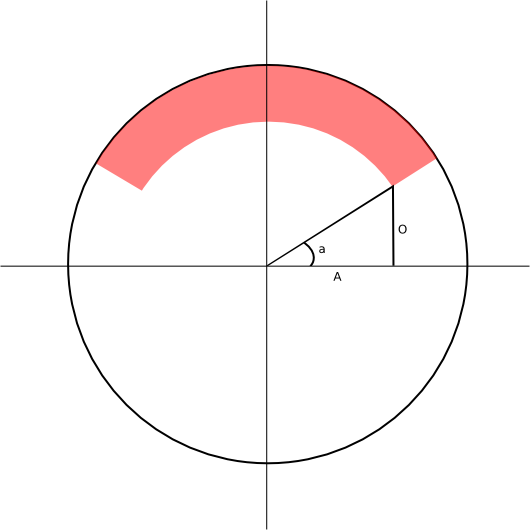
I couldn't think of a good method to actually recognise the curved text at the top so decided to use a 'dumb' approach. The curved text is in the same place on all the plaques so I built a system to apply the same mask to all the images. To do this I went back to what I could still remember from high school math lessons. To the probable delight of my old math teachers I quickly had some working code. The code I wrote cycles through all the pixels in the image and converts them to a distance and angle relative to the centre of the image. This process is hopefully easier to visualise in the image below. The distance is simple enough to calculate as we're dealing with a right-angle triangle; we simply square the x and y values, add them together and take the square root. The angle is a little trickier. The y-value represents the opposite length of the triangle and the x-value represents the adjacent length so from the mnemonic SOH CAH TOA we known the angle will be tan-1 (O/A). Knowing that we can then apply our rules for distance and angle.
Text Clean-up
The text clean-up was lots of little steps. Briefly I've,
- Made various improvements to the regexes for cleaning up the years
- Converted any instances of 'vv' (two v's) to 'w' (one w)
- Switched 0 (zero) to o (letter o) in words
- Removed any one/two character tokens from the end of the string
- Improved the selection of suggestions from the spell checker
- Broken up long words to see if a valid word can be found in the two halves
- Changed "s to 's
- Improved correction for endings where the ending is lived|worked|died here and the spelling checker returns bad results
- Removed any words containing three of lowercase, uppercase, digits and punctuation.
The regex for that last item is something of a monstrosity and as I'm far from an expert it wouldn't surprise me if it doesn't entirely do what I think it does. I've used whitespace to make it slightly easier to follow. Each line represents a sub-expression, if any sub-expression matches the string then the expression as a whole is considered to match. Each line matches a different combination of three from digits, lowercase, uppercase and punctuation. The .+ at the end means we match one or more of any character. The expressions in brackets starting with a question mark are look ahead assertions. The .+ still matches any character but the look ahead assertions state that at least one of the characters matched must be a digit for instance. It doesn't matter in what order the characters are present as long as they are present. If you suspect there is a flaw in the pattern or know some way to simplify it then I would really appreciate a quick note in the comments field below.
re.compile(r""" #matching a combination of digits, lowercase, uppercase and punctuation
((?=.*\d)(?=.*[a-z])(?=.*['"-,\.]).+| #d,l,p
(?=.*[A-Z])(?=.*[a-z])(?=.*['"-,\.]).+| #u,l,p
(?=.*\d)(?=.*[A-Z])(?=.*[a-z]).+| #d,u,l
(?=.*\d)(?=.*[A-Z])(?=.*['"-,\.]).+ #u,p,d
)""", re.VERBOSE)
That's all for now. I believe Ian is planning to run the competition for a further month and there are still considerable improvements to be made so it would be great to see more people taking part.