I'm writing this on the train back from Newcastle after attending this years Maker Faire. I've attended each Newcastle Maker Faire and it's been fantastic witnessing it grow each year. Many of the groups displaying their projects are veterans of previous Faires and it's inspiring seeing their projects develop from one year to the next. A growing faire means new groups and although some themes are repeated many groups have truly unique projects.
As last year I've put together a short video capturing some of the activity at this maker faire. It's difficult capturing more than a sliver of what makes this event great so I encourage you to click through to the project websites. I'll link to as many as I can below the video over the next few days but for the moment would encourage you to visit the official website.
Links
I can't find a link for the roving wheelie bins but more information on the fire breathing dragon is available here.
I can't find a link for the first robot. The second robot was from mbed. The third robot was part of a very large exhibit but again I'm struggling to find a link. The fourth scene of robots were from robochallenge. The final ground based bot was from robosavvy.
The underwater bot was from underwater rov. The aerial photography using a model plane was done by Simon Clark. The rocketry was from Black Streak.
It was difficult keeping track of all the 3D printers so I'll just highlight two focusing specifically on 3D printers - bodgeitquick and emakershop.
The first automata was from Richard Broderick, the second from Philip Lowndes and I'm unsure about the third though I suspect Richard again.
The standing wave flame tube was from Steve Mould. The wind up music disc was from the North of England Arduino Group organised by Mike Cook. I'm not sure who was responsible for the heart beat light sculpture. The interactive light table was built by Oli and the digital grafetti wall was built by the Jam Jar Collective and the musical tesla coils were from Brightarcs.
I've been using MDP and matplotlib a lot recently and although overall I've been very pleased with the documentation for both projects I have run into a few problems for which the solutions were not immediately obvious. This post gives the solution for each in the expectation it will certainly be useful to me in the future and the hope that it may also be useful to others.
Principal Component Analysis with MDP
Data Layout
The tutorial for the Modular Toolkit for Data Processing (MDP) starts with a quick example of using the toolkit for a pca analysis and yet I still ran into a couple of problems. The first issue I had was how the pca function expects to receive data. I suspect this is simply due to unfamiliarity with the field and the language used within the field. For future reference the data is expected to be in the following format.
Gene 1
Gene 2
Gene 3
Gene 4
Experimental Condition 1
.
.
.
.
Experimental Condition 2
.
.
.
.
Variance Accounted For in PC1, 2, etc
The previously mentioned quick start tutorial was very useful in getting something useful out quickly but I couldn't find a way to get a value for how much of the variance present in the data was accounted for in the principal components. To get that, as far as I've been able to determine, you need to interact with the PCANode directly rather than using the convenience function. The code is still relative straightforward.
importmdpimportnumpyasnpimportmatplotlib.pyplotasplt#Create sample datavar1=np.random.normal(loc=0.,scale=0.5,size=(10,5))var2=np.random.normal(loc=4.,scale=1.,size=(10,5))var=np.concatenate((var1,var2),axis=0)#Create the PCA node and train itpcan=mdp.nodes.PCANode(output_dim=3)pcar=pcan.execute(var)#Graph the resultsfig=plt.figure()ax=fig.add_subplot(111)ax.plot(pcar[:10,0],pcar[:10,1],'bo')ax.plot(pcar[10:,0],pcar[10:,1],'ro')#Show variance accounted forax.set_xlabel('PC1 (%.3f%%)'%(pcan.d[0]))ax.set_ylabel('PC2 (%.3f%%)'%(pcan.d[1]))plt.show()
Running this code produces an image similar to the one below.
Growing neural gas with MDP
The growing neural gas implementation was another sample application highlighted in the tutorial for MDP. It held my interest for a while as a technique which could potentially be applied to the transcription of plaques for the openplaques project. It wasn't immediately obvious how to get the position of a node from a connected nodes object. As the tutorial left the details of visualisation up to the user I'll present the solution to getting the node location in the form of the necessary code to visualise the node training. The end result will look something like the following.
Matplotlib
I've been using Matplotlib to plot data exclusively for a while now. The defaults produce reasonable quality graphs and any differences in opinion can be quickly fixed either by altering options in matplotlib or, as the graphs can be saved in svg format, in a vector image manipulation program such as Inkscape. Although most options can be changed in matplotlib it can sometimes be difficult to find the correct option. Most of the time the naming of variables are, to my mind, logical but sometimes I just can't find the right way to describe what I want to do.
Hiding axes
I wanted to have a grid of 6 graphs but didn't want to display the axes on all the graphs as I felt this looked cluttered.
Fixing the axis range
If I was going to display the axes on only some of the graphs then the values for the axes needed to be the same on all of them.
importnumpyasnpimportmatplotlib.pyplotasplt#Generate sample datavar=np.random.random_sample((40,2))fig=plt.figure()foriinrange(4):ax=fig.add_subplot(220+i+1)start=i*10ax.plot(var[start:start+10,0],var[start:start+10,1],'bo')#Hide the x axis on the top row of chartsifiin[0,1]:ax.set_xticklabels(ax.get_xticklabels(),visible=False)#Hide the y axis on the right column of chartsifiin[1,3]:ax.set_yticklabels(ax.get_yticklabels(),visible=False)#Set the axis rangeax.axis([0,1,0,1])plt.show()
Running this code should produce an image similar to the one below.
Removing second point in plot legend
The legend assumes that values are connected so two points and the connecting line are shown by default. If the points on the graph aren't connected then this looked strange. To remove the duplicate symbol is straightforward.
importnumpyasnpimportmatplotlib.pyplotasplt#Generate sample datavar=np.random.random_sample((10,2))#Plot data with labelsfig=plt.figure()ax=fig.add_subplot(111)ax.plot(var[0:5,0],var[0:5,1],'bo',label="First half")ax.plot(var[5:10,0],var[5:10,1],'r^',label="Second half")ax.legend(numpoints=1)plt.show()
A little over two months ago I wrote about the first round of the AI cookbook competition. Since then there have been two further rounds and a considerable amount of further progress. For the latest round I was able to get the error score down to 10.867 using an additional image pre-processing step and then a variety of text clean-up improvements.
Image Pre-processing
Ian, who writes the AI Cookbook, had the theory that the curved text present at the top of many of the plaques in the test set were causing tesseract, our OCR software of choice, significant problems in transcribing the main text. If we could automatically recognise the curved text and block it out the transcription should be significantly improved. In the diagram below the text we want to be transcribed is in green and the text we don't want is in red.
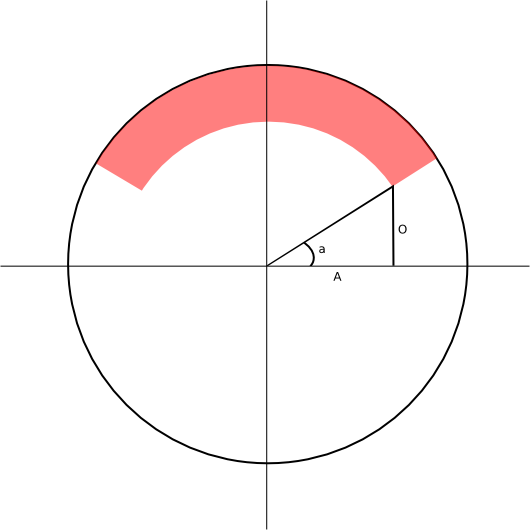
I couldn't think of a good method to actually recognise the curved text at the top so decided to use a 'dumb' approach. The curved text is in the same place on all the plaques so I built a system to apply the same mask to all the images. To do this I went back to what I could still remember from high school math lessons. To the probable delight of my old math teachers I quickly had some working code. The code I wrote cycles through all the pixels in the image and converts them to a distance and angle relative to the centre of the image. This process is hopefully easier to visualise in the image below. The distance is simple enough to calculate as we're dealing with a right-angle triangle; we simply square the x and y values, add them together and take the square root. The angle is a little trickier. The y-value represents the opposite length of the triangle and the x-value represents the adjacent length so from the mnemonic SOH CAH TOA we known the angle will be tan-1 (O/A). Knowing that we can then apply our rules for distance and angle.
Text Clean-up
The text clean-up was lots of little steps. Briefly I've,
Made various improvements to the regexes for cleaning up the years
Converted any instances of 'vv' (two v's) to 'w' (one w)
Switched 0 (zero) to o (letter o) in words
Removed any one/two character tokens from the end of the string
Improved the selection of suggestions from the spell checker
Broken up long words to see if a valid word can be found in the two halves
Changed "s to 's
Improved correction for endings where the ending is lived|worked|died here and the spelling checker returns bad results
Removed any words containing three of lowercase, uppercase, digits and punctuation.
The regex for that last item is something of a monstrosity and as I'm far from an expert it wouldn't surprise me if it doesn't entirely do what I think it does. I've used whitespace to make it slightly easier to follow. Each line represents a sub-expression, if any sub-expression matches the string then the expression as a whole is considered to match. Each line matches a different combination of three from digits, lowercase, uppercase and punctuation. The .+ at the end means we match one or more of any character. The expressions in brackets starting with a question mark are look ahead assertions. The .+ still matches any character but the look ahead assertions state that at least one of the characters matched must be a digit for instance. It doesn't matter in what order the characters are present as long as they are present. If you suspect there is a flaw in the pattern or know some way to simplify it then I would really appreciate a quick note in the comments field below.
re.compile(r""" #matching a combination of digits, lowercase, uppercase and punctuation ((?=.*\d)(?=.*[a-z])(?=.*['"-,\.]).+| #d,l,p (?=.*[A-Z])(?=.*[a-z])(?=.*['"-,\.]).+| #u,l,p (?=.*\d)(?=.*[A-Z])(?=.*[a-z]).+| #d,u,l (?=.*\d)(?=.*[A-Z])(?=.*['"-,\.]).+ #u,p,d )""",re.VERBOSE)
That's all for now. I believe Ian is planning to run the competition for a further month and there are still considerable improvements to be made so it would be great to see more people taking part.
Ian Ozsvald over at aicookbook has been doing some work using optical character recognition (OCR) to transcribe plaques for the openplaques group. His write-ups have been interesting so when he posted a challenge to the community to improve on his demo code I decided to give it a try.
The demo code was very much a proof of principle and its score of 709.3 was easy to beat. I managed to quickly get the score down to 44 and with a little more work reached 33.4. The score is a Levenshtein distance metric so the lower the better. I was hoping to get below 30 but in the end just didn't have time. I suspect it wouldn't take a lot of work to improve on my score. Here's what I've done so far . . .
Configure the system
All the work I've done was on an Ubuntu 10.04 installation and the instructions which follow will only deal with this environment. Beyond the base install I use three different packages:
Python Image Library
Used for pre-processing the images before submitting to tesseract
Tesseract
The OCR software used
Enchant spellchecker
Used for cleaning up the transcribed text
Their installation is straightforward using apt-get
Ian had posted a number of good suggestions on the wiki for how to improve the transcription quality. I used four approaches:
Image preprocessing
Cropping the image and converting to black and white takes the score from 782 (the demo code produced a higher score on my system than it did for Ian) to 44.6
Restricting the characters tesseract will return
By restricting the character set used by tesseract to alphanumeric characters and a limited selection of punctuation characters further lowered the score from 44.6 to 35.7
Spell checking
Running the results from tesseract through a spell checker and filtering out some common errors brought the score down to 33.4
I'll post the entire script at the bottom of this post but want to highlight a few of the key elements first.
The first stage of cropping the image on the plaque is handled by the function crop_to_plaque which expects a python image library image object. The function then reduces the size of the image to speed up processing before looking for blue pixels. A blue pixel is assumed to be any pixel where the value of the blue channel is 20% higher than both the red and green channels. The number of blue pixels in each row and column of the image is counted and then the image is cropped down to the rows and columns where the number of blue pixels is greater than 15% of the height and width of the image. This value is based solely on experimentation and seemed to give good results for this selection of plaques.
The next stage of converting the image to black and white is handled by the function convert_to_bandl which again expects a python image library image object. The function converts any blue pixels to white and all other pixels to black. Ian has pointed out that this approach might be overly stringent and I might get better results using some grey as well. The result of running these two functions on three of the plaques is shown below.
The next step was limiting the character set used by tesseract. The easiest way to do this is to create a file in /usr/share/tesseract-ocr/tessdata/configs/ which I called goodchars with the following content.
That selection of characters seems to include all the characters present in the plaques. To use this limited character set the call to tesseract needs to be altered to
Finally I perform a bunch of small clean up tasks. Firstly I fix the year ranges which frequently had extra spaces inserted and occasionally 1s appeared as i or l and 3 appeared as a parenthesis. These were fixed by a couple of regular expressions including one callback function (clean_years). Then I seperate the transcription out into individual words and fix a number of more issues including lone characters and duplicated characters before checking the spelling on any words of more than two characters.
Where next?
There is still lots of 'low hanging fruit' on this problem. At the moment the curved text at the top of the plaque and the small symbol at the bottom of the plaques is handled badly and I think the bad characters at the beginning and end of the transcriptions could be easily stripped out. The spelling corrections I make do overall reduce the error but they introduce some new errors. I suspect by being more selective in where spelling checks are made some of these introduced errors could be removed.
The entire script
importosimportsysimportcsvimporturllibfromPILimportImage# http://www.pythonware.com/products/pil/importImageFilterimportenchantimportre# This recognition system depends on:# http://code.google.com/p/tesseract-ocr/# version 2.04, it must be installed and compiled already# plaque_transcribe_test5.py# run it with 'cmdline> python plaque_transcribe_test5.py easy_blue_plaques.csv'# and it'll:# 1) send images to tesseract# 2) read in the transcribed text file# 3) convert the text to lowercase# 4) use a Levenshtein error metric to compare the recognised text with the# human supplied transcription (in the plaques list below)# 5) write error to file# For more details see:# http://aicookbook.com/wiki/Automatic_plaque_transcriptiondefload_csv(filename):"""build plaques structure from CSV file"""plaques=[]plqs=csv.reader(open(filename,'rb'))#, delimiter=',')forrowinplqs:image_url=row[1]text=row[2]# ignore id (0) and plaque url (3) for nowlast_slash=image_url.rfind('/')filename=image_url[last_slash+1:]filename_base=os.path.splitext(filename)[0]# turn 'abc.jpg' into 'abc'filename=filename_base+'.tif'root_url=image_url[:last_slash+1]plaque=[root_url,filename,text]plaques.append(plaque)returnplaquesdeflevenshtein(a,b):"""Calculates the Levenshtein distance between a and b Taken from: http://hetland.org/coding/python/levenshtein.py"""n,m=len(a),len(b)ifn>m:# Make sure n <= m, to use O(min(n,m)) spacea,b=b,an,m=m,ncurrent=range(n+1)foriinrange(1,m+1):previous,current=current,[i]+[0]*nforjinrange(1,n+1):add,delete=previous[j]+1,current[j-1]+1change=previous[j-1]ifa[j-1]!=b[i-1]:change=change+1current[j]=min(add,delete,change)returncurrent[n]deftranscribe_simple(filename):"""Convert image to TIF, send to tesseract, read the file back, clean and return"""# read in original image, save as .tif for tesseractim=Image.open(filename)filename_base=os.path.splitext(filename)[0]# turn 'abc.jpg' into 'abc'#Enhance contrast#contraster = ImageEnhance.Contrast(im)#im = contraster.enhance(3.0)im=crop_to_plaque(im)im=convert_to_bandl(im)filename_tif='processed'+filename_base+'.tif'im.save(filename_tif,'TIFF')# call tesseract, read the resulting .txt file back incmd='tesseract %s%s -l eng nobatch goodchars'%(filename_tif,filename_base)print"Executing:",cmdos.system(cmd)input_filename=filename_base+'.txt'input_file=open(input_filename)lines=input_file.readlines()line=" ".join([x.strip()forxinlines])input_file.close()# delete the output from tesseractos.remove(input_filename)# convert line to lowercasetranscription=line.lower()#Remove gaps in year rangestranscription=re.sub(r"(\d+)\s*-\s*(\d+)",r"\1-\2",transcription)transcription=re.sub(r"([0-9il\)]{4})",clean_years,transcription)#Separate wordsd=enchant.Dict("en_GB")newtokens=[]print'Prior to post-processing: ',transcriptiontokens=transcription.split(" ")fortokenintokens:if(token=='i')or(token=='l')or(token=='-'):passeliftoken=='""':newtokens.append('"')eliftoken=='--':newtokens.append('-')eliflen(token)>2:ifd.check(token):#Token is a valid wordnewtokens.append(token)else:#Token is not a valid wordsuggestions=d.suggest(token)iflen(suggestions)>0:#If the spell check has suggestions take the first onenewtokens.append(suggestions[0])else:newtokens.append(token)else:newtokens.append(token)transcription=' '.join(newtokens)returntranscriptiondefclean_years(m):digits=m.group(1)year=[]fordigitindigits:ifdigit=='l':year.append('1')elifdigit=='i':year.append('1')elifdigit==')':year.append('3')else:year.append(digit)return''.join(year)defcrop_to_plaque(srcim):scale=0.25wkim=srcim.resize((int(srcim.size[0]*scale),int(srcim.size[1]*scale)))wkim=wkim.filter(ImageFilter.BLUR)#wkim.show()width=wkim.size[0]height=wkim.size[1]#result = wkim.copy();highlight_color=(255,128,128)R,G,B=0,1,2lrrange={}forxinrange(width):lrrange[x]=0tbrange={}foryinrange(height):tbrange[y]=0forxinrange(width):foryinrange(height):point=(x,y)pixel=wkim.getpixel(point)if(pixel[B]>pixel[R]*1.2)and(pixel[B]>pixel[G]*1.2):lrrange[x]+=1tbrange[y]+=1#result.putpixel(point, highlight_color)#result.show();left=0right=0cutoff=0.15forxinrange(width):if(lrrange[x]>cutoff*height)and(left==0):left=xiflrrange[x]>cutoff*height:right=xtop=0bottom=0foryinrange(height):if(tbrange[y]>cutoff*width)and(top==0):top=yiftbrange[y]>cutoff*width:bottom=yleft=int(left/scale)right=int(right/scale)top=int(top/scale)bottom=int(bottom/scale)box=(left,top,right,bottom)region=srcim.crop(box)#region.show()returnregiondefconvert_to_bandl(im):width=im.size[0]height=im.size[1]white=(255,255,255)black=(0,0,0)R,G,B=0,1,2forxinrange(width):foryinrange(height):point=(x,y)pixel=im.getpixel(point)if(pixel[B]>pixel[R]*1.2)and(pixel[B]>pixel[G]*1.2):im.putpixel(point,white)else:im.putpixel(point,black)#im.show()returnimif__name__=='__main__':argc=len(sys.argv)ifargc!=2:print"Usage: python plaque_transcribe_demo.py plaques.csv (e.g. \easy_blue_plaques.csv)"else:plaques=load_csv(sys.argv[1])results=open('results.csv','w')forroot_url,filename,textinplaques:print"----"print"Working on:",filenametranscription=transcribe_simple(filename)print"Transcription: ",transcriptionprint"Text: ",texterror=levenshtein(text,transcription)assertisinstance(error,int)print"Error metric:",errorresults.write('%s,%d\n'%(filename,error))results.flush()results.close()
About a month ago I came across Kaggle which provides a platform for prediction competitions. It's an interesting concept. Accurate predictions are very useful but designing systems to make such predictions is challenging. By engaging the public it's hoped that talent not normally available to the competition organiser will have a try at the problem and come up with a model which is superior to previous efforts.
Prediction is not exactly my area of expertise but I wanted to have a crack at one of the competitions currently running; predicting response to treatment in HIV patients. I haven't yet started developing a model but wanted to release the python framework I've put together to test ideas. It can be downloaded here.
I've included a number of demonstration prediction methods; randomly guessing, assuming all will respond or assuming none will respond. I suggest you start with one of these methods and then improve on it with your own attempt. The random method was my first submission which, at the time of writing, currently puts me in 30th position out of 33 teams. Improving on that shouldn't be difficult.
During development you can use the bootstrap class to get an idea of how well your method works as demonstrated above. All the training data is split randomly into training and testing sets and then the method trained on the training set and assessed on the test set. This process is repeated, the default is 50 times, and the the scores returned. The score returned will be different to the score when you submit but hopefully should give you an indication of how well you're doing.
When you are satisfied with your method you can create the file needed for submission using the above code. In this case we are sticking with the random method. The submission file is submission1.csv. Hopefully this code is useful to you and you'll submit a prediction method yourself.